Synopsis of Proposed Paper
MRSI 21st Annual Market Research Seminar
Abhishek Sanwaliya
Senior Analyst, CRM
Absolutdata Inc., India
Anurag Srivastava
Senior Analyst, DGA
Dell Inc., India
Munish Gupta
Marketing Director
Dell Inc., Texas
Keisha Daruvalla
Marketing Consultant
Dell Inc., Texas
Abstract |
Social media marketing propagates the need for trend analysis to capture brand advocacy. Presence in the social sphere can be judged by the segmented sentiments which quantify a product’s brand image. The sentiment analysis is benchmarked as a key indicator to measure brand advocacy. One way to tap into the potential of unstructured data is through text analytics. Text analytics is the practice of semi-automatically aggregating and exploring textual data to obtain new insights by combining technology, industry knowledge, and practices that drive business outcomes. The text processing conceptualizes effective text filtration and classification. The stabilized Social Net Advocacy (SNA) platform projects structured visualization of sentiment analysis to measure sentiments for structured customer journeys.
Introduction |
The virtue of social media presence has brought the need for real-time sentiment monitoring to evaluate brand advocacy. The best practice utilizes key text-mining modules, such as categorization and sentiment analysis. The past work done in this domain was significant when measured for real-time monitoring augmented by effective visualization. The previous practice was constrained to provide analysis at a broad level, with no segment level attribute. The Social Net Advocacy (SNA#) tool has been developed to analyze segment-level customer journeys (sentiment score) with effective visualization. The pre-filtration task performed by RapidMiner
SNA provides ease of visualization that helps to figure out a customer’s share of voice about products, components, stages of the customer journey (for both commercial and consumer customers), and business functions. Each category and subcategory includes a breakdown of sentiment—positive, negative and neutral, along with the number of posts devoted to that topic and the change in SNA score over the past time frame. This real-time feature provides a reflexive social media response that can set the guidelines for actionable strategy to channelize social media marketing.
Methodology |
The contributed research captured the essentials of text-mining modules to get structured sentiment analysis using the SNA visualization feature. The RapidMiner’s capability for handling unstructured data using text-processing modules (viz. tokenizing, stemming, filtration, term frequencies, document frequencies & TFIDF) induced proactive text-content management and utilized it to evaluate the raw text-processing filtration efficiency. The exploratory advanced implementation of structured classification and sentiment scoring scaled on a broad spectrum (-100 to +100) using the SNA tool. The SNA score gives quantified measurements and a sense of brand advocacy for structured customer journeys. The typical sequence synchronized and developed the segmented score valuation system with measurable flow of social media data aggregation, processing, tuning, classification and sentiment scoring.
Text Preprocessing |
In order to produce efficient results with high accuracy, first we excluded the terms that were semantically insignificant. We applied basic modules for text pre-processing to ensure the data sanity for better results. Table 1 includes pre-processing steps:
Table 1 Table 1: Pre-processing of Text
| Module | Description |
| Normalization | Toobtainauniformtext,weadoptnormalization,inwhichwe convert text to lowercase so that the distinction between uppercaseandlowercaseisignored. |
| Tagging | Part-of-speech(POS)taggingis theprocessofassigninga part-of-speech, suchasnoun,verb,pronoun,preposition, adjective orotherlexicalclassmarker, toeachwordina sentence.Itisbasedon“ThePennTreebankTagset”[7] |
| Tokenization | Tokenization is the process of reducing a message to itscolloquialcomponents |
| Dimension Reduction |
Dimensionalityreductionisaprocesstoreducethespaceofadocument. It involves the removal ofthenon-contextwords thatoccurwith veryhighfrequency inmostdocuments anddonotcarryany semantic meaning for categorization, and hence are insignificantin makingdistinctionsamongdifferentdocuments. |
| Stemmingand Lemmatization |
Stemming most commonly collapses derivationally relatedwords, whereas lemmatization only collapses the different inflectionalformsofa lemma.[5] |
The combined effect of text filtration yields a feature set having huge potential to produce efficient and effective classification. Dimension reduction provides improved efficiency by selecting relevant terms to prepare a feature set. As a result of stemming and lemmatization, an effective feature set is prepared to achieve higher efficiency. Pre-filtration has a major impact on classification accuracy.
Feature Set Preparation |
A feature set is defined as a set of words (or phrases) that specifies a particular class and accordingly helps a classification algorithm to discern the boundary of one class from that of another. We used unigrams and bigrams, extracted from text, as the contents of the feature set. However, we use this methodology because we want to focus on identifying a distinct set of features. We made use of two types of feature sets: (1) Bi-grams approach: a set consisting of frequently occurring words with a particular class and (2) Unigram Approach: a word cluster with similar semantic context. They are based on the concept of word co-occurrence.
A. Bi-gram Feature Selection
A co-occurred phrase is a word pair that frequently occurs in a typical sequence in documents belonging to a same class. It is not necessary that they follow the same sequence, but they should follow the syntactic sequence of nearby words. It enables us to prepare well-distinguished co-occurred phrases which are strongly associated with their class and have a potential to discriminate among available categories. Another facet is to select terms having high frequency in order to reduce the noise of data. Complexity in classification increases with an increased size of feature set. For efficient and prominent classification, however, it is not easy to select such a set of word pairs; due to the inherent complexities, a strong association between a bigram and a class is necessary. A number of bigrams is initially compiled after removing stop-words. To determine a strong association between a bigram and a particular class, the information gain measure was employed [3]. To determine the characteristic of a category, we concentrate on sentences containing topic tag names explicitly, and then consolidate whole information to determine the class. Correlation between bigrams and class clearly determines the category of the customer journey.
B. Unigram Feature Selection
Another method for identifying a feature set is the unigrams approach, which utilizes clustering of words into groups of similar concepts. The word similarity is estimated by co-occurrence between two words in a sentence. The word similarity index provides a good approximation of co-occurrence. In this approach, we measure the similarity by computing the cosine angle between two word vectors. This provides an insight that the more frequent the co-occurred word in a document, the higher the similarity value. We applied the concept of Latent Semantic Analysis (LSA) due to lack of semantically similar group detection ability of conventional weight-based methods. To capture semantic coherence, we use LSA [6]. We represent our feature set as an original word document matrix to capture the semantic coherence of the text. Then, we extract most important single factor to measure the covariance of an inverted matrix. This way, LSA captures the “semantic” value of a given text document. It becomes easier to trace the similarity of documents using LSA, as it represents text in a subjective way, as compared to a conventional approach in which all weight goes to high-frequency terms. A word in the identified vocabulary is represented as a word vector. A hierarchical agglomerative clustering [4], [1] is employed to group words. Unigram enables us to prepare feature sets that can provide better results.
Classification: |
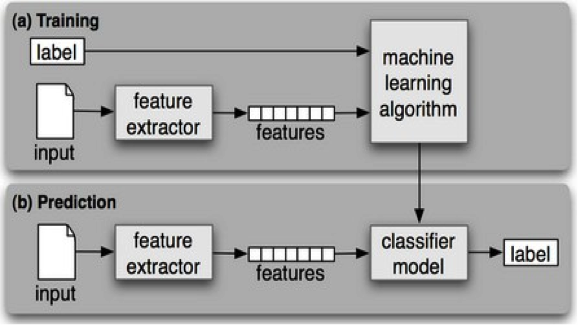
A Decision Tree is a basic flow technique that selects labels for input values. This flowchart consists of decision nodes, which check feature values, and leaf nodes, which assign labels. To choose the label for an input value, we begin at the flowchart’s initial decision node, known as its root node. This node contains a condition that checks one of the input value’s features, and selects a branch based on that feature’s value. Following the branch that describes our input value, we arrive at a new decision node, with a new condition on the input value’s features. We continue following the branch selected by each node’s condition, until we arrive at a leaf node that provides a label for the input value.
Once we have a decision tree, it is straightforward to use it to assign labels to new input values. What’s less straightforward is how we can build a decision tree that models a given training set. But before we look at the learning algorithm for building decision trees, we’ll consider a simpler task: picking the best decision stump for a corpus. A decision stump is a decision tree with a single node that decides how to classify inputs based on a single feature. It contains one leaf for each possible feature value, specifying the class label that should be assigned to inputs whose features have that value. In order to build a decision stump, we must first decide which feature should be used. The simplest method is to just build a decision stump for each possible feature, and see which one achieves the highest accuracy on the training data, although there are other alternatives, which we will discuss below. Once we have picked a feature, we can build the decision stump by assigning a label to each leaf based on the most frequent label for the selected examples in the training set (i.e., the examples where the selected feature has that value).
Given the algorithm for choosing decision stumps, the algorithm for growing larger decision trees is straightforward. We begin by selecting the overall best decision stump for the classification task. We then check the accuracy of each of the leaves on the training set. Leaves that do not achieve sufficient accuracy are then replaced by new decision stumps, trained on the subset of the training corpus that is selected by the path to the leaf.
Figure 1: Supervised Machine Learning Approach
Experimental Results: SNA Analysis |
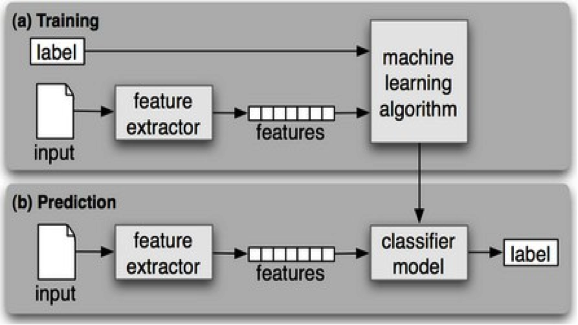
This section discusses the sentiment analysis experimented over real-time social media posts for one month (April 2013, arbitrated for sake of confidential interest). The pre-processing and data preparation created efficient and clearly defined boundaries for their respective categories. The aggregated data for the product line were classified under two broad categories viz. customer journey – consumer and commercial. The classified categories synchronized with the SNA tool to visualize the sentiment trends both at the macro and micro level.
Figure 2: Post Volume & SNA Trend for Customer Journey-Consumer
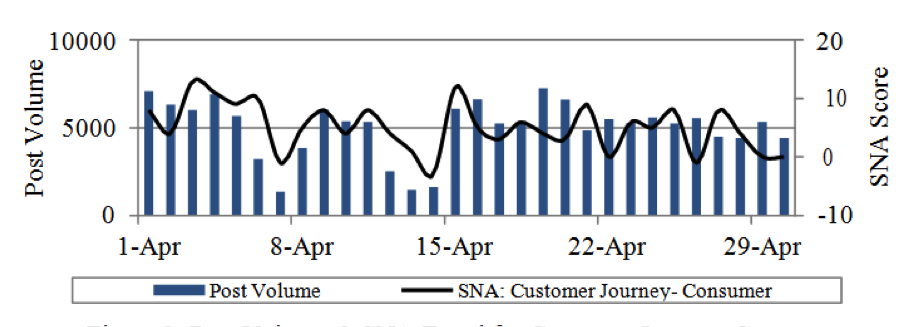
The SNA tool provides layered sentiments distributed across themes captured for customer journeys.
Figure 3: Post Volume & SNA Trend for Consumer Segment
The fluctuation in the SNA trend (Fig. 3), along with post volume distribution, signifies the aggregated raves, rants and neutral sentiment across consumer segments. The advocacy can be visualised by SNA scores associated with key themes depicted for customer journeys across prime consumer segments.
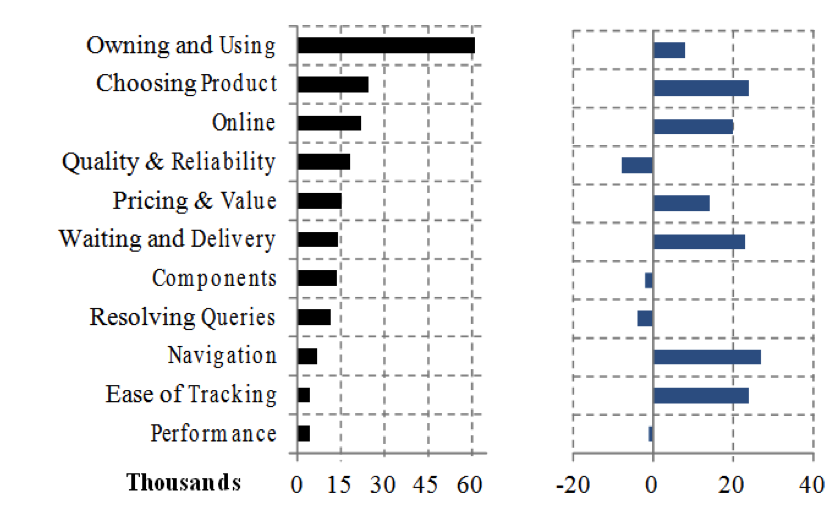
Figure 4: Post Volume & SNA Trend for Customer Journey-Commercial
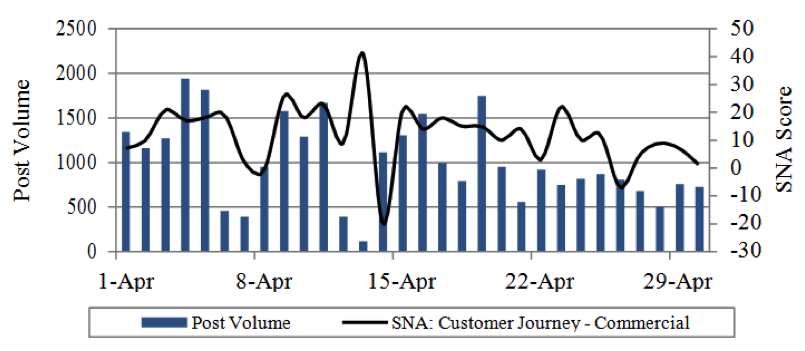
The commercial segment contains less post volume (Fig. 4) due to its Business-to-Business nature, which yields less social media presence as compared to the consumer segment.
Figure 5: Post Volume & SNA Trend for Commercial Segment
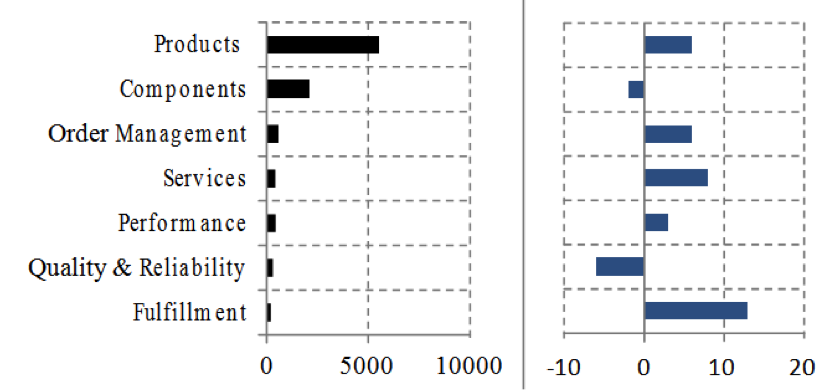
The product-related posts lead the segment, but with neutral sentiment. Components and quality and reliability-related issues rated with negative SNA, but performance, order management, fulfillment, and services show positive footprints.
The SNA is a competent measure to showcase and understand the customer/client’s perception and journey throughout the process, until the deal gets accomplished. This shows a real window that can be implemented as an actionable task and synchronized with a real-time campaign to make social media marketing more visible and actionable.
Conclusion |
By taking insights from available social media posts, we introduced application of text classification and sentiment analysis to predict the brand advocacy by accessing the customer journey – both consumer and commercial. Text classification enormously utilizes the combined concepts of feature extraction and information gain along with sentiment scoring using SNA. The SNA scoring is capable of showcasing trends at a segment and sub-segment level. With the proposed SNA scoring and visualization technique, we are able to signify the brand advocacy in terms through the multi-point sentiment scoring technique, which has the capability to score over a 100-point scale with pin-point magnitude measurement. The successful results support that the proposed algorithms effectively work in this task, though the domain of the classification problem was confined; despite this, we obtained promising results. However, the proposed method has several weak points associated with NLP engine limitation that prevent it from reaching a performance above 70% accuracy when measured on precision accuracy for supervised learning. Failure of our approach takes place when we have a commensurate number of co-located phrases of each class and sarcastic statements, as it is then difficult to determine the class. To cope with these problems, we are considering employing several natural language processing techniques that can provide discriminative views about misclassification. We are also projecting the approach using discriminate term extraction with coherent semantic structure. We are developing the capability of SNA, through which we can do competitor analysis, keeping taxonomy structure and phases of transition.
Acknowledgements |
We would like to take this opportunity to express our sincere gratitude toward our mentor, Mr. Rajiv Narang (Executive Director, Dell Inc.), who incubated the concept of SNA. It would have never been possible for us to take this research to its destination without his ideas, relentless support and encouragement. We’d also like to extend a word of appreciation to Absolutdata for their text-mining engagement with Dell Global Analytics (DGA). Special thanks to Mr. Sudeep Goswami (Senior Manager, Strategy Marketing and Sales Analytics, DGA) for showing confidence in us and providing us with a great incubation environment to shape this research at DGA. Thanks to Mr. Guhan P (Sr. Business Advisor, DGA) for his expert mentorship.
References |
- A.Jainand R.Dubes.AlgorithmsforClusteringData.PrenticeHall,1988.
- Rapidminerhttps://rapid-i.com
- A.McCallumandK.Nigam.EmployingEMandpool-basedactivelearning fortextclassification. InProceedings ofInternationalConferenceonMachine Learning,pages359–367,1998.
- S.Dumais.Usingsvms fortextcategorization.IEEEIntelligentSystems,13(4), 1998.
- PorterStemmer,https://tartarus.org/~martin/PorterStemmer
- S.Deerwester,S.Dumais,G.Furnas,T.Landauer, andR.Harshman.Indexing bylatentsemanticanalysis.JournaloftheAmericanSocietyforInformation Science,41(6):391–407,1990.
- Penn Treebank Tag set http://www.ims.unistuttgart.de/projekte/Corpus Workbench/CQP-HTMLDemo/PennTreebankTS.html
- MinqingHu.andBingLiu.Miningandsummarizingcustomerreviews,KDD ‘4: Proceedings of the 10th ACM SIGKDD international conference on knowledgediscoveryanddatamining,2004
# Social Net Advocacy (SNA) Tool is at Beta version stage which is researched and maintained by Social Media Team at Dell Inc.
If this got you thinking and wanting for more, contact us here or write to us at adt.marketing@absolutdata.com


























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}