Food for Thought Experiment | Neuroevolution
Neural networks have become the state-of-the-art algorithm for solving many complex problems in today’s world. However, one of the major challenges of using neural networks is to find the best architecture (i.e. number of hidden layers, number of neurons, etc.), which relies heavily on human experts. Neuroevolution is a machine learning technique where neural network architecture is developed through the use of evolutionary algorithms. It allows us to add/remove a node, update weighted connections, etc., thus creating a robust method for network development. Here the aim is to minimize dependency on human experts by evolving the network topologies in an automated manner.
Evolutionary Algorithm
Initially, we start with a randomly chosen population of neural network architectures which are trained on different datasets. Each neural network architecture is then evaluated on validation set using a fitness function (objective function). The fitness function could be an accuracy score in classification problems or a RMSE (root mean square error) in regression problems.
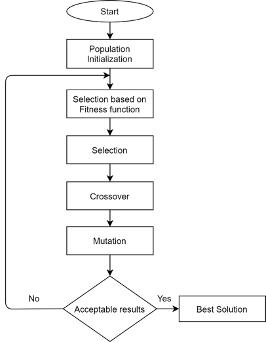
Fig 1: Flow chart of Genetic algorithm Adapted from TowardsDataScience.com [1]
Architectures with good fitness scores are chosen to be parents and undergo reproduction: the parent architectures are replicated and mutated to generate child architectures. These child architectures are then evaluated on the validation set; they replace architectures with poor fitness scores in the population. Once the child architecture becomes part of the population, they are free to act as parents in next steps.[2] These steps in succession will allow the best architecture to replicate themselves in newer generation; thus, the population evolves until a network with a sufficiently high fitness score is found.
Using the above strategy increases the search space significantly for complex image models. To achieve computational efficiency in such scenarios, the above algorithm can be executed in a massively parallel infrastructure. Here, many workers will operate simultaneously on different computers that do not communicate with each other. They only use a shared file system where the population is stored. [2]
Mutation
The mutation process allowed child architectures to be different from their parent architectures while still inheriting some of the parents’ properties. There is a predefined set of mutations out of which a mutation is selected at random during each reproduction event. This predefined set can change learning rates, change weight connections, insert or remove a convolution, change stride/filter size, and add/remove/skip, etc. mutations.
These mutations represent actions that a human expert would have taken to improve the performance of the architecture. These simple mutations and the selection process allow the network to improve over time and perform well on the validation set (although the validation set was never exposed to the architecture). Thus, along with developing the architecture, the population trains its network while exploring the search space. Hence the process returns a fully trained network along with optimized hyperparameters, without the intervention of human expert once the experiment starts. [3]




















