
Bidirectional Encoder Representations from Transformers – or BERT for short – is a neural-network-based pre-training technique for natural language processing applications. Pre-training a neural network can help businesses tremendously by reducing the time required to launch a product or system. The improvement BERT offers over previous implementations is the ability to learn bidirectional contextual representations. This means that it can learn from the context before and after the token word. (See example below.) Using pre-trained BERT models that can be fine-tuned by adding just one output layer helps data scientists create state-of-the-art models for a wide range of NLP tasks.

BERT can capture both the right and the left context of the token word “bank”.
If we use a pre-trained contextual representation like ELMo or ULMFit to process the text given above, it will fail in at least one case, as it can deal with either the left or right context. Context-free models like Word2vec and GloVe will not be able to make use of the context; they will produce the same result for “bank” in both cases.
To evaluate the performance of BERT, it was compared with state-of-the-art NLP systems on SQuAD, a reading comprehension dataset consisting of questions. BERT, when it was showcased, achieved a 93.2% F1 score (a measure of accuracy), which was much better than the state-of-the-art score of 91.6% and the human score of 91.2%. Today, variations of BERT dominate the SQuAD leaderboard, as seen in the image below.
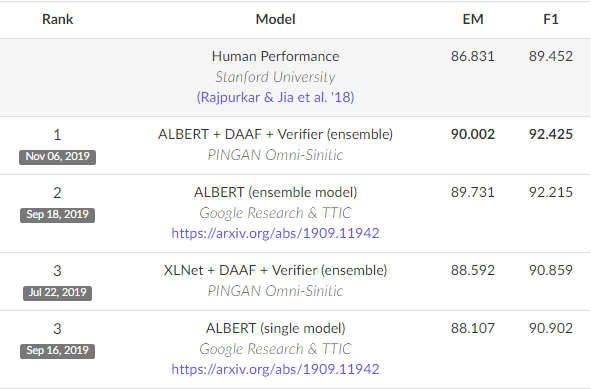
Ranking of models derived from BERT on the SQuAD dataset.
An example on Google’s Search blog showed that BERT is able to grasp the meaning of complex phrases like “2019 brazil traveler to usa need a visa”. Previously, this would have returned results about U.S. citizens traveling to Brazil instead of Brazilian citizens traveling to the U.S. BERT allows Google to improve results for 10% of their searches. Another major advantage of BERT is that it allows the system to take the learnings of one language and apply them to other languages.
Businesses can now leverage the power of BERT to solve NLP tasks in mere hours. Google open-sourced the codebase and the pre-trained models, which can be found on GitHub. You can learn more about the technical details of BERT from Google’s paper BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding.
References
- https://www.blog.google/products/search/search-language-understanding-bert/
- https://ai.googleblog.com/2018/11/open-sourcing-bert-state-of-art-pre.html
- https://github.com/google-research/bert
- https://arxiv.org/abs/1810.04805
- https://rajpurkar.github.io/SQuAD-explorer/
Technical articles are published from the Absolutdata Labs group, and hail from The Absolutdata Data Science Center of Excellence. These articles also appear in BrainWave, Absolutdata’s quarterly data science digest.




















