
The world of social media is advancing rapidly. This has resulted in the collection of copious amounts of data in the form of unstructured text. This text, although very useful, can be hard to interpret in its original form. If businesses want to use hyperpersonalization to improve customer satisfaction, it is vital for them to understand such data. The current capability of text analysis tools and techniques does not fully leverage a human’s ability to visualize and make sense of text data. This can be facilitated by converting unstructured text to a set of organized images that enable visualization.
Currently, there is only one way to analyze unstructured texts in bulk: isolating sentences, words, themes, and subjects via a tool (i.e. NLP). When parts of speech are organized into a table format, we can get a glimpse of the meaning within the text.
Two techniques are widely used for visualization: tag clouds and word trees.
Tag Clouds: As the name suggests, a tag cloud is a ‘cloud of words’ where words are prioritized based on their occurrence within the text. Fonts, colors, and backgrounds are used to indicate how often each word occurs. This sounds simple, but it gives a very good general idea of the data.
Tag clouds are widely used to analyze the speeches of various political, business, and social leaders. Moreover, by comparing two tag clouds we can understand the basic theme and the main focus area of two subjects.
Below is a tag cloud for a speech delivered by Steve Jobs. Looking at the importance of words depicted in the cloud (“college”, ”life”, ”year”, “course”, “looking”, ”death”), it’s evident that the different phases of life were emphasized in this speech. Guess what? This is the cloud for his Stanford commencement address.
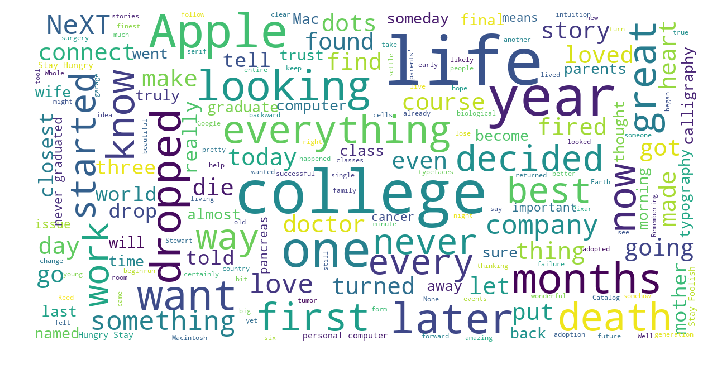
The above tag cloud was created using the WordCloud open-source library. Find out more about WordCloud at https://github.com/amueller/word_cloud
Word Tree: A word tree uses a tree structure to visually represent words that follow a search term. This allows the viewer to examine how a word or a sequence of words is used in a text. Word trees are especially useful in finding and exploring patterns, but they also enable the user to delve into individual details.[1] This visualization technique was invented by Martin Wattenberg and Fernanda Viégas.
Word trees are mainly used for texts with a repetitive structure. For example, in “A Portrait of the Artist as a Young Man”, the term “His soul” appears 83 times, but it is followed by such different phrases as “was fattening”, “was festering”, “was soaring”, “was waking”, “was enriched”. [2]
The word tree below shows multiple parallel sequences of words. Words that are strongly associated are displayed with a thicker typeface; this not only represents the relationship but also signifies the strength of the association. The hierarchy of words arranges the text data into an organized pattern, which is much easier to comprehend. Moreover, we do not need to go through the entire text; we can simply search for the required portion.[3]
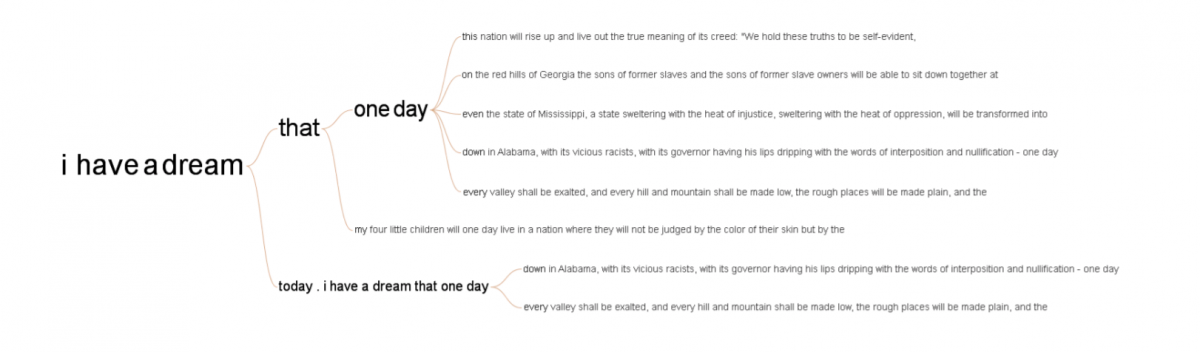
A word tree showing all occurrences of “I have a dream” in Dr. Martin Luther King Jr.’s historic speech. [4]
References
[1][2][3][4] from “The Word Tree, an Interactive Visual Concordance” by Martin Wattenberg and Fernanda B. Viégas. http://hint.fm/papers/wordtree_final2.pdf
Technical articles are published from the Absolutdata Labs group, and hail from The Absolutdata Data Science Center of Excellence. These articles also appear in BrainWave, Absolutdata’s quarterly data science digest.




















