Statistictionary | Meta learning and its statistical approaches
Overview
Meta learning is synonymous with “learning to learn”. Our usual machine learning models require many data samples for training. The basic idea behind meta learning is to teach the machine about learning to learn, like a human infant would. Kids who ride a bicycle are faster at learning to ride a motorcycle. Humans can grasp a new idea or skill very quickly – people who have never seen Georges Braque’s Fauvist paintings would quickly learn to differentiate them from Paul Cezanne’s Post-Impressionist works. This is because people can leverage their previous experiences and apply them to a similar problem.
Meta learning aims to design a machine learning model capable of generalizing and adapting to new tasks and new environments never encountered during training.
The goal of the model is to improve the learning algorithm itself; this provides an opportunity to tackle the existing challenge of data and computation bottlenecks and the generalization challenge in deep learning.
Examples of meta learning tasks are:
- A classifier trained on cat-bird images can differentiate images of dogs from images of otters after seeing just a few dog images.
- A game bot can quickly master a new game.
The basic mathematics of meta learning work by executing a model update in two stages, as illustrated below [1]:
- A classifier, f θ, is the “student” model, trained to operate a specified task.
- Simultaneously, an optimizer, gΦ (the teacher model), learns how to update the parameters of the “student” model through the support set S, θ’ = gΦ( θ,S).
And later, for optimization, both θ and Φ are optimized to maximize.[2]
Meta Learning Algorithms
There are three basic approaches to meta learning. These are taken from Lilian Weng’s work Meta-Learning: Learning to Learn Fast [2] :
- Model-based – Model-based learning is swift-paced. Even after just a few training steps, this approach works on updating its parameters, which can be achieved by another meta-learned model or by its own internal architecture.
- Metric-based – The general thinking behind metric-based meta learning is generating a model which aims to learn a distance or metric function over objects. A good metric model is dependent on how well a kernel is successful in problem solving.
- Optimization-based – These meta learning algorithms are intended to adjust the optimization algorithm. The current approach involves learning through the backpropagation of gradients, which requires a large number of training samples.
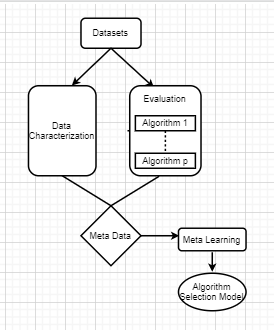
Fig1: The meta-learning process for algorithm selection [3]
In the end, meta learning aims to build an AI model that, without training from scratch, can learn to perform various tasks based on previous experiences. Every time we try to learn a task, we gain experience for future tasks – regardless of whether our current attempts are successful or not. [1]
References
- An Introduction to Meta-Learning
https://medium.com/walmartlabs/an-introduction-to-meta-learning-ced7072b80e7 - Meta-Learning: Learning to Learn Fast
https://lilianweng.github.io/lil-log/2018/11/30/meta-learning.html#metric-based - Optimization-Based Meta-Learning
https://www.researchgate.net/figure/The-meta-learning-process-for-algorithm-selection-adapted
Technical articles are published from the Absolutdata Labs group, and hail from The Absolutdata Data Science Center of Excellence. These articles also appear in BrainWave, Absolutdata’s quarterly data science digest.




















