Unsupervised Learning (Like Clustering) Using Random Forest
This is fifth in a series of seven Segmentation and Clustering articles. It outlines a procedure for turning typical supervised learning methods into unsupervised methods.
A New Approach
Machine learning methods are often categorized as supervised (outcome labels are used) or unsupervised (outcome labels are not used).
Most of us are of the opinion that techniques like Random Forest, SVM, Logistic, etc. can only be used for supervised learning. However, many supervised methods can be turned into unsupervised methods using the following procedure:
An artificial class label is created that distinguishes the ‘observed’ data from suitably generated ‘synthetic’ data. The observed data is the original unlabeled data, while the synthetic data is drawn from a reference distribution. Supervised learning methods, which distinguish observed data from synthetic data, yield a dissimilarity measure that can be used as input in subsequent unsupervised learning methods
As stated above, many unsupervised learning methods require the inclusion of an input dissimilarity measure among the observations. Hence, if a dissimilarity matrix can be produced using Random Forest, we can successfully implement unsupervised learning. The patterns found in the process will be used to make clusters.
How Do We Generate a Dissimilarity Matrix?
- Terminal tree nodes contain few observations. If case ‘i‘ and case ‘j’ both land in the same terminal node, we increase the similarity between ‘i’ and ‘j’ by 1.
- At the end of the run, divide by 2 x no. of trees.
- Dissimilarity = sqrt(1-Similarity).
Illustration
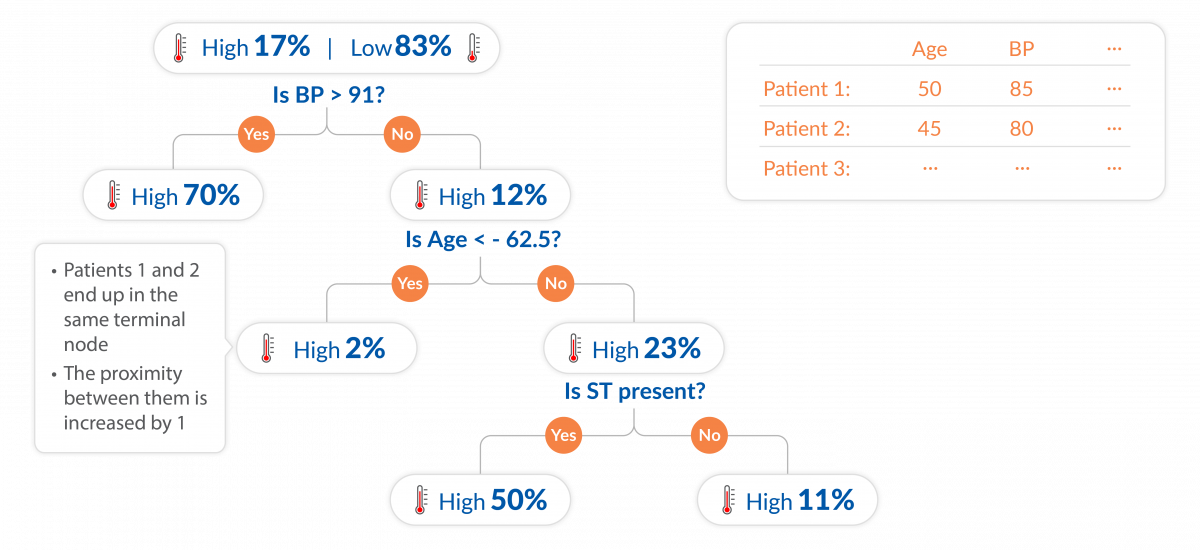
Steps for Random Forest Clustering
- Label the observed data as class 1.
- Generate synthetic observations and label them as class 2.
- There are two standard ways of generating synthetic observations:
- Independent sampling from each of the univariate distributions of the variables (Addcl1 =independent marginals).
- Independent sampling from uniforms, such that each uniform has a range equal to the range of the corresponding variable (Addcl2).
- There are two standard ways of generating synthetic observations:
- Construct an RF predictor to distinguish class 1 from class 2.
- Use the resulting dissimilarity measure in unsupervised analysis.
- Compute distance matrix from RF: distance matrix = sqrt(1-similarity matrix).
- Conduct partitioning around medoid (PAM) clustering analysis where the input parameter = no. of clusters k.
Random Forest Clustering in Research
RF dissimilarity has been successfully used in several unsupervised learning tasks involving genomic data:
- Breiman and Cutler (2003) applied RF clustering to DNA microarray data.
- Allen et al. (2003) applied it to genomic sequence data.
- Shi et al. (2004) applied it to tumor-marker data.
In these real data applications, the resulting clusters often made sense in their biology applications, which provides indirect empirical evidence that this method works well in practice.
Random Forest Clustering in Research in R
Following are the files which has sample data and Implementation of Random Forest Clustering in R.


References
- https://horvath.genetics.ucla.edu/html/publications/FullManuscriptRFclustering1_final.pdf
- https://horvath.genetics.ucla.edu/rfclustering/
- http://ftp.cse.buffalo.edu/users/azhang/disc/disc01/cd1/out/papers/cikm/p20.pdf
Technical articles are published from the Absolutdata Labs group, and hail from The Absolutdata Data Science Center of Excellence. These articles also appear in BrainWave, Absolutdata’s quarterly data science digest.




















